Amazon Kinesis ułatwia zbieranie, przetwarzanie i analizowanie danych strumieniowych w czasie rzeczywistym dzięki czemu można uzyskać aktualny wgląd w dane i szybko reagować na nowe informacje. Amazon Kinesis oferuje kluczowe możliwości efektywnego kosztowo przetwarzania danych strumieniowych w dowolnej skali, wraz z elastycznością związaną z wyborem narzędzia, które najlepiej pasuje do wymagań aplikacji.
Dzięki Amazon Kinesis można pobierać dane w czasie rzeczywistym takie jak audio, video, logi aplikacji, dane telemetryczne IoT do uczenia maszynowego, analizy i innych zastosowań. Usługa pozwala na przetwarzanie i analizowanie danych w miarę ich napływu i natychmiastową reakcję zamiast czekania, aż wszystkie dane zostaną zebrane przed rozpoczęciem przetwarzania.
Gdzie możemy wykorzystać Amazon Kinesis?
Usługa znajduje zastosowanie w sytuacjach w których wymagamy szybko zmieniających się danych i ich ciągłego przetwarzania. Kinesis może być użyty w następujących sytuacjach:
Przetwarzanie logów: nie musimy czekać na skompletowanie wszystkich danych, możemy w czasie rzeczywistym dodawać dane do strumienia zaraz po ich wytworzeniu. Dodatkowa korzyść z wykorzystania Amazon Kinesis to zabezpieczenie danych w przypadku awarii urządzenia, tj. logi systemowe czy aplikacyjne mogą być stale dodawane do strumienia przez co mamy do nich bardzo szybko dostęp kiedy są potrzebne;
Wykresy w czasie rzeczywistym: możemy tworzyć wykresy/metryki używając strumienia Amazon Kinesis do tworzenia raportów wynikowych. Nie musimy czekać na poszczególne partie danych;
Analiza danych: dzięki usłudze możemy uruchomić analizę danych strumieniowych w czasie rzeczywistym.
Jakie limity nakłada nam Amazon Kinesis?
Zanim zaczniemy pracować nad swoimi projektami musimy również pamiętać o ograniczeniach jakie nakłada na nas Amazon Kinesis:
rekordy strumienia danych są dostępne maksymalnie przez 24 godziny (ustawienia domyślne) – mogą być przedłużone do 7 dni dzięki włączeniu rozszerzonej retencji danych. Jeżeli nie wiecie czym jest retention policy - jest to polityka za pomocą której definujemy czas dostępności danych np. w S3 czy DynamoDB - im dłużej przetrzymujemy dane tym więcej musimy zapłacić dlatego wprowadza się takie polityki celem ograniczenia kosztów;
maksymalny rozmiar danych binarnych (blob - pozwala na przechowywanie dużych ilości danych binarnych jako pojedyczny obiekt w bazie danych) w jednym rekordzie to 1 megabajt;
jeden shard obsługuje do 1000 operacji PUT na sekundę. Już spieszę z wyjaśnieniem. Shard jest pojęciem związanym ze skalowaniem bazy danych w poziomie w przypadku gdy nasza baza danych zaczyna "puchnąć" pod wypłem napływu kolejnych danych. Przechowywanie wielu danych z których codziennie korzysta wielu użytkowników prowadzi często do timeout’ów, dead’loków czy długo wykonujących się zapytań. Rozwiązaniem, w bardzo dużym skrócie, jest poziome skalowanie bazy danych, tzw. data sharding. Proces ten polega na podzieleniu jednej, dużej bazy danych, na wiele mniejszych (stąd określenie pojedynczego shard’a). Samego podziału możemy dokonać na kilka sposobów ale nie jest to temat na ten wpis.
Cechy charakterystyczne Amazon Kinesis
Przetwarzanie w czasie rzeczywistym: usługa pozwala na zbieranie i analizowanie informacji w czasie rzeczywistym, np. cen akcji.
Łatwość użycia: dzięki usłudze możemy stworzyć nowy strumień, określić jego wymagania i szybko rozpocząć strumieniowanie danych.
Interoperacyjność: usługa może być zintegrowana z S3, DynamoDB czy Redshift.
Tworzenie różnych aplikacji: Amazon Kinesis dostarcza biblioteki, które umożliwiają projektowanie i działanie aplikacji przetwarzających dane w czasie rzeczywistym.
Zrównoważony koszt: podobnie jak w przypadku wszystkich poprzednio opisanych usług płacimy za wykorzystywane zasoby oraz wymaganą przepustowość (w skali godzinowej) w zależności od skali obciążeń, które generujemy.
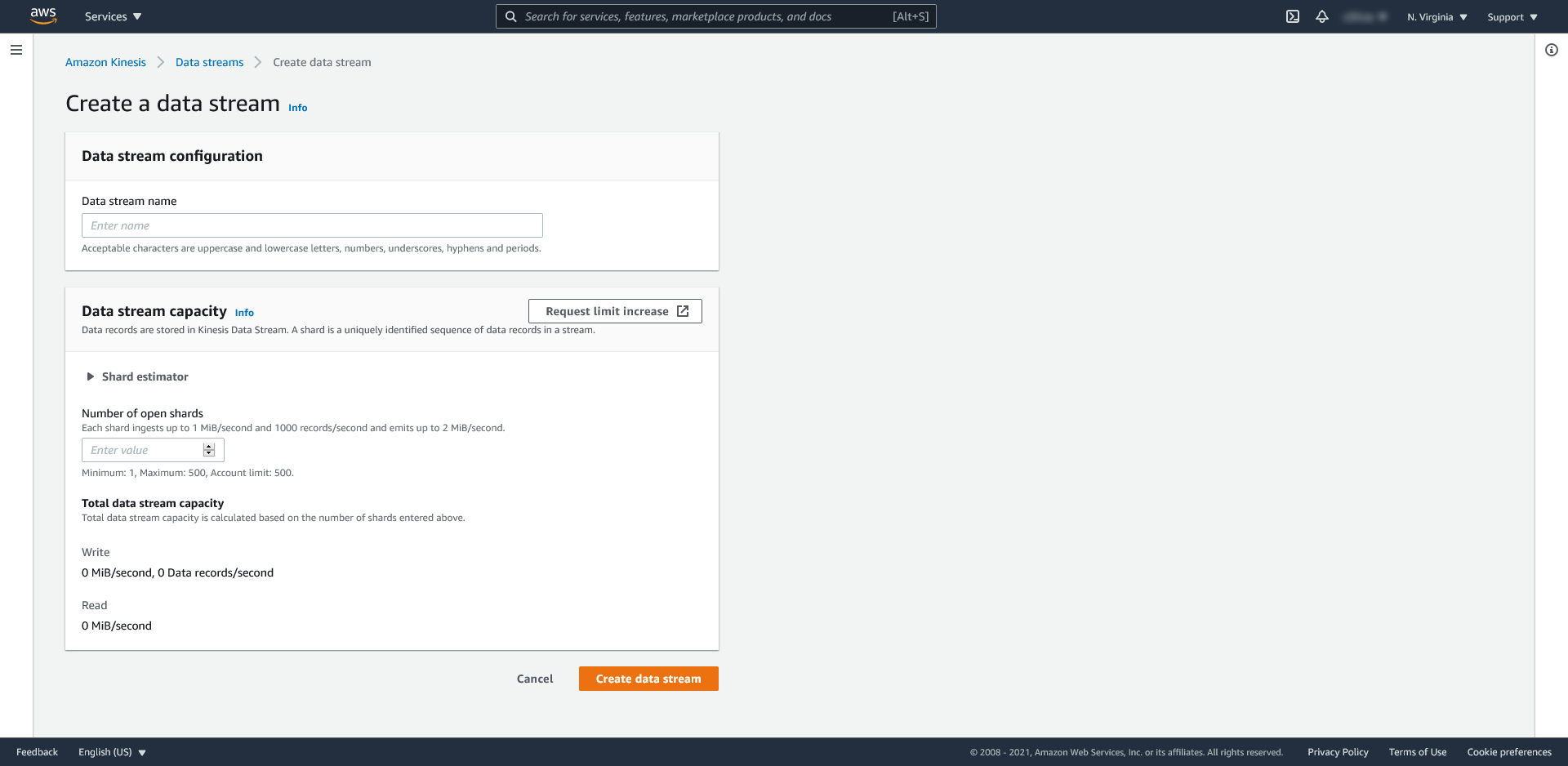
Z poziomu otwartego okna wybieramy Kinesis Data Streams a następnie klikamy przycisk Create data stream.
Wypełniamy pola obowiązkowe takie jak nazwa strumienia oraz liczba shard’ów, tj. jednoznacznie zidentyfikowana sekwencja rekordów w danych w strumieniu. W moim przypadku wybrałem wartość minimalną, tj. 1:
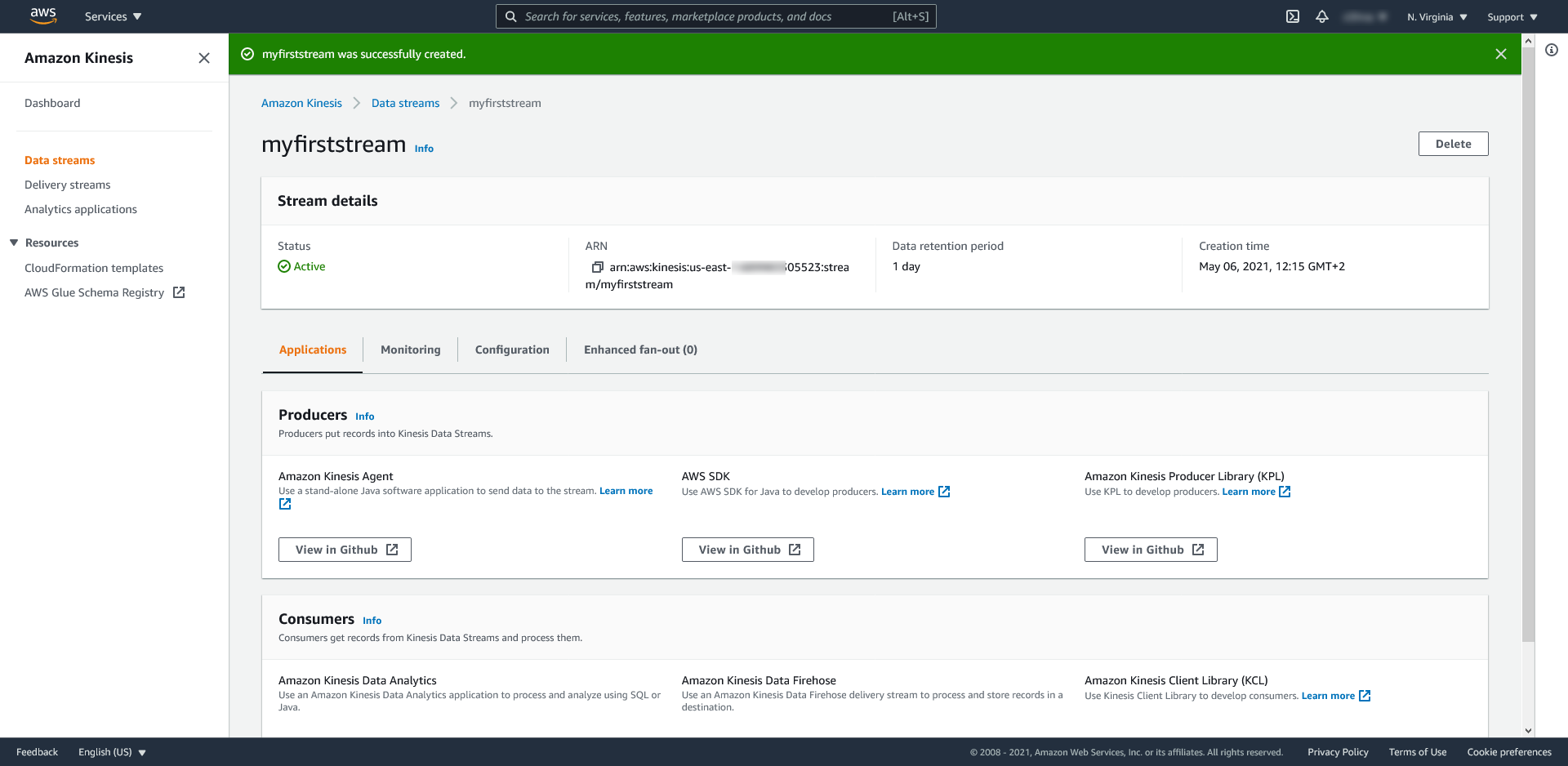
Strumień został utworzony i pozostaje widoczny:
W tym momencie jesteśmy gotowi na kolejne kroki, tj. właściwą implementację funkcjonalności. Ten krok przewidziałem jednak na kolejną serię ponieważ ta jest wprowadzeniem do usług i ogólnym ich zrozumieniu. Jeżeli jednak jesteście ciekawi dalszych kroków odsyłam Was pod adres https://aws.amazon.com/kinesis/data-analytics/getting-started/ gdzie możecie rozpocząć swoją przygodę i utworzyć pierwszą aplikację Amazon Kinesis Data Analytics.
W jednym z wpisów w kolejnym cyklu napiszemy aplikację, która będzie dodawała dane do strumienia, zdarzenie to wywoła nam funkcję Lambda, która wyślę wiadomość email w celu poinformowaniu o zdarzeniu – wszystko w oparciu o język C#.