Wracamy po dłuższej przerwie...kontynuujemy naszą przygodę z AWS a w tej serii zapoznamy się z DynamoDB.
Dlaczego tak? DynamoDB stanowi nieodłączny element architektury AWS a poprzednie dwa cykle były ogólnym wprowadzeniem do nowych zagadnień. Warto jednak skupić się na szczegółach danego rozwiązania, aby w przyszłości tworzyć szybsze i bardziej skalowalne aplikacje. Pomijając podstawowe aspekty techniczne do których należy tworzenie tabel, pobieranie czy aktualizowanie danych skupimy się na odpowiedniej defincji tabel, definiowaniu kluczy głównych czy wzorcach dostępu do danych, które pozwolą na efektywniejsze wykorzystanie tabeli.
Porozmawiamy również o przepustowości, wydajności, rozmiarach, kosztach dostępu czy alternatywnych sposobach przechowania dużych zestawów danych. Porównamy sposoby odczytu danych, omówimy tworzenie indeksów, zajmiemy się monitorowaniem aktywności zachodzących w danej tabeli oraz spojrzymy na obsługę błędów. To tylko niektóre z zagadnień, które poruszymy w tym cyklu.
Zanim przejdziecie do kolejnych wpisów warto zajrzeć do poprzednich artykułów w których możecie przeczytać m.in. o tworzeniu tabeli oraz praktycznym jej wykorzystaniu w połączeniu z funkcją Lambda:
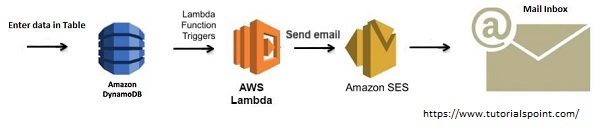
W ramach przypomnienia możecie przeanalizować poniższą, prostą architekturę aplikacji z wykorzystaniem DynamoDB: