Operacja Scan w przypadku DynamoDB odczytuje każdy element w tabeli lub indeksie wtórnym. Domyślnie operacja ta zwraca wszystkie atrybuty dla każdego elementu w tabeli lub indeksie. Możemy jednak użyć parametru ProjectionExpression, aby Scan zwrócił tylko niektóre atrybuty.
Operacja skanowania zawsze zwraca zestaw wyników. Jeżeli nie zostaną znalezione żadne pasujące elementy, zestaw wyników jest pusty.
Pojedyncze żądanie Scan może maksymalnie pobrać 1MB danych. Opcjonalnie DynamoDB może zastosować wyrażenie filtrujące do tych danych zawężając wyniki zanim zostaną zwrócone użytkownikowi.
W tym wpisie przejdziemy przez kilka pojęć, do których zaliczamy wyrażenia filtrujące dla skanowania, liczenie elementów w wynikach, omówimy jednostki pojemności zużywane przez operację skanowania oraz zerkniemy na spójności odczytu dla skanowania. Zacznijmy od wyrażeń filtrujących.
Wyrażenia filtrujące
Jeżeli potrzebujemy zawęzić wyniki skanowania możemy opcjonalnie podać wyrażenie filtrujące. Wyrażenie filtrujące określa, które elementy w wynikach skanowania powinny być zwrócone do użytkownika. Wszystkie inne wyniki są odrzucane.
Wyrażenie filtrujące jest stosowanie po zakończeniu skanowania, ale przed zwróceniem wyników. W związku z tym operacja Scan zużywa tyle samo pojemności odczytu niezależnie od obecności wyrażenia filtrującego.
Operacja skanowania może pobrać maksymalnie 1MB danych. Ten limit ma zastosowanie przed wykonaniem wyrażenia filtrującego.
W przypadku operacji skanowania można określić dowolne atrybuty w wyrażeniu filtrującym – w tym atrybut klucza partycji i klucza sortowania.
Składnia wyrażenia filtrującego jest identyczna jak składnia wyrażenia warunkowego. Wyrażenia filtrujące mogą używać tych samych komparatorów, funkcji i operatorów logicznych, co wyrażenia warunkowe.
O przykładach porozmawiamy więcej w kolejnym wpisie, w którym skupimy się na użyciu kodu a nie wprowadzaniu teoretycznym.
Ograniczenie liczby elementów w zbiorze wyników
Operacja Scan umożliwia ograniczenie liczby elementów, które zwraca w wyniku. W tym celu należy wykorzystać parametr Limit, aby określić maksymalną liczbę elementów, którą chcemy, żeby operacja zwróciła przed wykonaniem wyrażenie filtrującego.
W ramach przykładu załóżmy, że skanujemy tabelę z wartością Limit ustawioną na 8 i bez wyrażenia filtrującego. Wyniki skanowania zwróci pierwsze osiem elementów z tabeli.
Załóżmy teraz, że dodajemy wyrażenie filtrujące. W tym przypadku DynamoDB stosuje wyrażenie filtrujące do ośmiu zwróconych elementów, odrzucając te, które nie pasują. Końcowy wynik skanowania zawiera osiem lub mniej elementów w zależności od liczby elementów, które zostały przefiltrowane.
Paginacja wyników
DynamoDB dzieli wynik skanowania na strony. W przypadku paginacji wyniki skanowania są dzielone na "strony" o rozmiarze 1MB lub mniejszym. Aplikacja może przetwarzać pierwszą stronę wyników, następnie drugą i tak dalej.
Pojedyncze skanowanie zwraca tylko taki zestaw wyników, który mieści się w limicie 1MB.
Aby określić czy jest więcej wyników i pobrać je na jednej stronie powinniśmy wykonać poniższe kroki:
sprawdzić wyniki skanowania niskiego poziomu:
jeżeli wynik zwraca element LastEvaluatedKey przejść do kroku 2;
jeżeli w wyniku nie ma elementu LastEvaluatedKey to nie ma żadnych elementów do pobrania;
przygotować nowe żądanie Scan z tymi samymi parametrami, co poprzednie. Tym razem jednak musimy wziąć wartość LastEvaluatedKey z kroku pierwszego i użyć, jako parametru ExclusiveStartKey w nowym żądaniu Scan.
uruchomić nowe żądanie skanowania.
przejść do korku 1.
Innymi słowy, LastEvaluatedKey z odpowiedzi skanowania powinien być użyty, jako ExclusiveStartKey dla następnego żądania Scan. Jeżeli w odpowiedzi skanowania nie ma elementu LastEvaluatedKey, to znaczy, że została pobrana ostatnia strona wyników. Brak tego klucza to jedyny sposób, aby wiedzieć, że dotarłeś do końca zestawu wyników.
Liczba elementów w wyniku
Oprócz elementów spełniających Twoje kryteria odpowiedź Scan zawiera następujące elementy:
ScannedCount - liczba przeskanowanych elementów przez zastosowaniem jakiegokolwiek filtra ScanFilter. Wysoka wartość ScannedCount przy niewielu lub braku wyników Count wskazuje na nieefektywną operację skanowania. Jeżeli w żądaniu nie zastosowano filtra, ScannedCount jest taki sam jak Count;
Count - ilość elementów, które pozostały przy zastosowaniu wyrażenia filtrującego (jeżeli występuje).
Tutaj musimy pamiętać, że jeżeli nie zostało zastosowane wyrażenie filtrujące to ScannedCount i Count mają taką samą wartość.
Jeżeli rozmiar zestawu wyników skanowania jest większy niż 1MB, ScannedCount i Count reprezentują tylko częściowe zliczenie wszystkich elementów. Musisz wykonać wiele operacji Scan, aby pobrać wszystkie wyniki.
Każda odpowiedź Scan zawiera ScannedCount i Count dla elementów, które zostały przetworzone przez konkretne żądanie Scan. Aby uzyskać sumę całkowitą dla wszystkich żądań Scan, możesz zachować bieżący bilans zarówno ScannedCount jak i Count.
Jednostki pojemności zużyte przez skanowanie
Operację skanowania możemy wykorzystać na dowolnej tabeli lub indeksie wtórnym. Operacje skanowania zużywają jednostki pojemności odczytu w następujący sposób:
Jeżeli skanujesz...
DynamoDB zużywa jednostki pojemności do odczytu z...
Tabelę
Pojemność odczytu tabeli
Globalny indeks wtórny
Pojemność odczytu indeksu
Lokalny indeks wtórny
Pojemność odczytu tabeli podstawowej
Domyślnie operacja Scan nie zwraca żadnych danych na temat ilości zużywanej pojemności odczytu. Można jednak wykorzystać parametr ReturnConsumedCapacity w żądaniu, aby uzyskać te informacje. Poniżej prawidłowe ustawienia dla wspomnianego parametru:
NONE - nie są zwracane żadne dane o zużytej pojemności (jest to ustawienie domyślne);
TOTAL - odpowiedź zawiera łączną liczbę zużytych jednostek pojemności odczytu;
INDEXES - odpowiedź zawiera zagregowaną liczbę zużytych jednostek pojemności odczytu wraz z zużytą pojemnością dla każdej tabeli i indeksu, do których uzyskano dostęp.
DynamoDB oblicza liczbę zużytych jednostek pojemności odczytu na podstawie rozmiaru elementu a nie ilości danych zwracanych do aplikacji. Z tego powodu liczba zużytych jednostek pojemności jest taka sama niezależnie od tego czy żądasz wszystkich atrybutów (zachowanie domyślne) czy tylko niektórych z nich (używając wyrażenia projekcji). Liczba ta jest również taka sama niezależnie od tego czy używasz wyrażenie filtrującego czy nie. Scan zużywa minimalną jednostkę pojemności odczytu (0.5 przy domyślnym zachowaniu eventually consistent oraz 1.0 przy zachowaniu strongly consistent) dla każdej partycji biorącej udział w obsłudze żądania – dotyczy to również partycji nie zawierających żadnych elementów.
Spójność odczytu
Operacja Scan wykonuje domyślnie spójne odczyty. Oznacza to, że wyniki skanowania mogą nie zawierać zmian spowodowanych ostatnio wykonanymi operacjami PutItem lub UpdateItem.
Jeżeli wymagany jest silnie spójny odczyt od momentu rozpoczęcia skanowania, należy ustawić parametr ConsistentRead na wartość true w żądaniu skanowania. Dzięki temu wszystkie operacje zapisu, które zakończyły się przed rozpoczęciem skanowania, zostaną uwzględnione w operacji skanowania.
Ustawienie parametru ConsistentRead na wartość true może być przydatne w scenariuszach tworzenia kopii zapasowych tabel lub replikacji w połączeniu ze strumieniami DynamoDB. W pierwszej kolejności używamy skanowania z parametrem ConsistentRead ustawionym na true, aby uzyskać spójną kopię danych z tabeli. Podczas operacji skanowania DynamoDB Streams rejestruje każdą dodatkową aktywność zapisu, która występuje na tabeli. Po zakończeniu skanowania możemy zastosować aktywność zapisu ze strumienia do tabeli.
Jedyne, o czym musimy pamiętać to fakt, że ustawienie parametru ConsistentRead na true zużywa dwa razy więcej jednostek pojemności w porównaniu do pozostawienia wartości parametru na wartości domyślnej, tj. false.
Skanowanie równoległe
Domyślnie operacja Scan przetwarza dane sekwencyjnie. DynamoDB zwraca dane do aplikacji w krokach, co 1MB a aplikacja wykonuje dodatkowe operacje Scan, aby pobrać kolejny 1MB danych.
Im większa tabela lub indeksy tym więcej czasu zajmuje skanowanie. Dodatkowo, skanowanie sekwencyjne może nie zawsze być w stanie w pełni wykorzystać przepustowość odczytu: nawet, jeśli DynamoDB dystrybuuje dane dużej tabeli na wiele fizycznych partycji, operacja Scan może odczytać tylko jedną partycję w tym samym czasie. Z tego powodu przepustowość operacji skanowania jest ograniczona przez maksymalną przepustowość pojedynczej partycji.
Aby rozwiązać te problemy operacja Scan może logicznie podzielić tabelę lub indeks wtórny na wiele segmentów a wielu pracowników aplikacji (tzw. worker thread) może równolegle skanować segmenty. Każdy robotnik (worker) może być wątkiem (w językach programowania obsługujących wielowątkowość) lub procesem systemu operacyjnego. Aby wykonać skanowanie równoległe, każdy robotnik/wątek wydaje własne żądanie skanowania z następującymi parametrami:
Segment - segment, który ma być skanowany przez danego pracownika. Każdy robotnik powinien używać innej wartości dla segmentu;
TotalSegments - całkowita liczba segmentów dla skanowania równoległego. Wartość taka musi być taka sama jak liczba robotników, których będzie używała Twoja aplikacja.
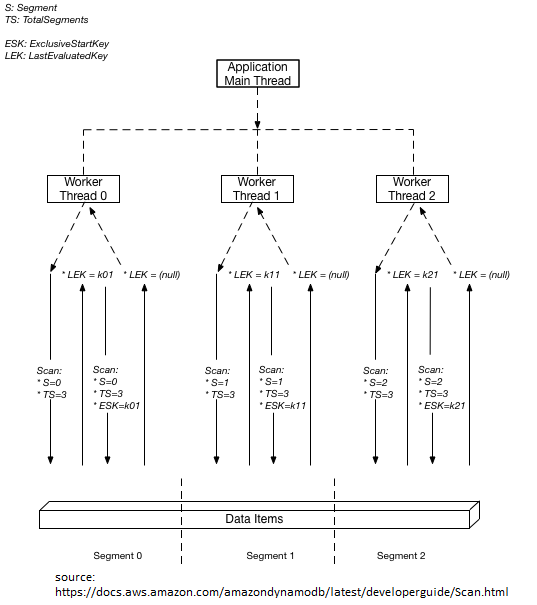
Poniższy diagram pokazuje jak wielowątkowa aplikacja wykonuje równoległe skanowanie z trzema stopniami równoległości:
Na powyższym diagramie możecie zobaczyć, że aplikacja tworzy trzy wątki i przypisuje każdemu z nich numer. (Segmenty są liczone od zera, więc pierwszy z nich to zawsze 0). Każdy wątek wystawia żądanie Scan ustawiając Segment na wyznaczony numer i ustawiając parametr TotalSegments na 3. Każdy wątek skanuje wyznaczony segment pobierając dane po 1MB na raz i zwraca dane do głównego wątku aplikacji,
Wartość Segment i TotalSegments dotyczą poszczególnych żądań Scan i w każdej chwili można użyć innych wartości. Oczywiście jest to przykład i w naszych aplikacjach prawdopodobnie będziemy musieli eksperymentować z tymi wartościami i liczbą używanych robotników/watków, aż nasza aplikacja osiągnie najlepsza wydajność.
Musimy jeszcze pamiętać, że skanowanie równoległe z dużą liczbą robotników może łatwo zużyć całą przepustowość tabeli lub indeksu. Najlepiej jest unikać takiego skanowania, jeżeli tabela lub indeks są obciążone dużą aktywnością odczytu lub zapisu przez inne aplikacje.
Aby kontrolować ilość danych zwracanych na żądanie powinniśmy używać parametru Limit - dzięki temu unikniemy sytuacji, w której jeden robotnik zużywa całą przewidzianą przepustowość kosztem pozostałych robotników.
To tyle, jeżeli chodzi o teorię. W kolejnym wpisie popiszemy przykłady wykorzystując technologię .NET.