Adnotacja:
Jeden z moich Czytelnikow (github: oscyp) dostrzegł błąd w poniższym wpisie. Korzystając z nowszej wersji frameworka niż ja zauważył, że bazuję jedynie na 6 przeciążeniach metody Split(...) a nie 10, jak to ma miejsce
w przypadku .NET Core 3.1.
Prześledziłem dostępną dokumentację - artykuł bazował na .NET Core 1.1 (niestety nie mam już dostępu do tej maszyny). Poniżej zaktualizowany (dzięki!) artykuł bazujący na .NET Core 3.1.
Niestety czasy intensywnej pracy na front-end'em doprowadził do takiej pomyłki (Wybaczcie za wprowadzanie w błąd! Dzięki również za uważne czytanie artykułów!).
Wprowadzenie
Jest to pierwszy z serii kilku artykułów wpis dotyczący pisania wydajnego kodu w języku C#. Od pewnego czasu jestem ściśle związany z językiem JavaScript i technologiami czysto webowymi. Jednakże w trakcie tego projeku jeden z klientów zaczął zgłaszać problemy z wydajnością i czasem przetwarzania danych w starszej wersji aplikacji. Okazało się, że dziennie system (w jego przypadku) przetwarza blisko 20 milionów rekordów...
Z pozoru nie zastanawiamy się na oszczędnością kilku milisekund przy przetwarzaniu danych. Każdy z nas przywykł do pewnej implementacji i nie zastanawia się czy są lepsze rozwiązania. W tym jednak wypadku należało prześledzić dokładnie kod, porównać różne podejścia i wyciągnać stosowne wnioski. Seria tych artykułów ma na celu podsumowanie tych obserwacji. Pamiętajcie jednak, że pomiary, który będziemy dokonywać (a raczej różnice między nimi) są naprawdę znaczące dopiero przy przetwarzania ogromnynych ilości danych.
String Split
W przypadku .NET Core 3.1 mamy do dyspozycji 10 przeciążeń metody Split(...):
public String[] Split(char[] separator, int count, StringSplitOptions options);
public String[] Split(char separator, int count, StringSplitOptions options = StringSplitOptions.None);
public String[] Split(char separator, StringSplitOptions options = StringSplitOptions.None);
public String[] Split(params char[] separator);
public String[] Split(char[] separator, int count);
public String[] Split(char[] separator, StringSplitOptions options);
public String[] Split(String separator, int count, StringSplitOptions options = StringSplitOptions.None);
public String[] Split(String separator, StringSplitOptions options = StringSplitOptions.None);
public String[] Split(String[] separator, int count, StringSplitOptions options);
public String[] Split(String[] separator, StringSplitOptions options);
Większość z nas używa poniższej implementacji:
string text = "Audi|RS6";
string[] test = text.Split('|');
Zastanawialiście się kiedyś czy jest to najwydajniesze rozwiązanie?
Zmienimy nasze podejście: zamiast bezpośredniego przekazania znaku stworzymy tablicę znaków a nasz separator przekażemy jako element zdefiniowanej tablicy:
string[] test2 = text.Split(new char[] { '|' });
W powyższym podejściu pomijamy etap interpetacji związany z wywołaniem dodatkowego kodu (związanego ze słowem kluczowym params, które przyjmuje zmienną liczbę parametrów):
public String[] Split(char[] separator, int count, StringSplitOptions options);
W przypadku naszej implementacji pojedyczny element jest interpretowany jako jednoczęściowa tablica znaków.
Sprawdźmy teraz w praktyce porównianie czasów wykonania powyższych implementacji:
static void Main(string[] args)
{
Stopwatch s1 = new Stopwatch();
s1.Start();
string text = "Audi|RS6";
string[] test = text.Split('|');
Console.WriteLine(s1.ElapsedTicks.ToString());
Stopwatch s2 = new Stopwatch();
s2.Restart();
string[] test2 = text.Split(new char[] { '|' });
Console.WriteLine(s2.ElapsedTicks.ToString());
Console.ReadKey();
}
Różnica jest naprawdę znacząca (.NET Core 1.1):
 A w przypadku .NET Core 3.1 jeszcze większa:
A w przypadku .NET Core 3.1 jeszcze większa:
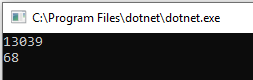 Niestety bezpośrednie porównanie nie jest możliwe w tym przypadku (proszę nie wyciągajcie pochopnych wniosków) - aktulizacja artykułu zostana wykonana na całkowicie innym sprzęcie/procesorze i systemie operacyjnym.
Niestety bezpośrednie porównanie nie jest możliwe w tym przypadku (proszę nie wyciągajcie pochopnych wniosków) - aktulizacja artykułu zostana wykonana na całkowicie innym sprzęcie/procesorze i systemie operacyjnym.
