Paweł Łukasiewicz
2019-01-04
Paweł Łukasiewicz
2019-01-04
Wprowadzenie
Kateregoria przypisania tego artykułu nie jest najlepsza, gdyż tutaj skupimy się na analizie technicznej a nie konkretnej implementacji. Jest to jednak uzupełnienie lektury dwóch poprzednich artykułów związanych z RabbitMQ dlatego zdecydowałem się na taką kategoryzację (.NET Core – komunikacja pomiędzy serwisami przy użyciu RabbitMQ oraz .NET Core – RabbitMQ: UI, CLI, przypadki użycia). Obracamy się ciągle w obrębie technologii .NET Core.
Odpowiedzmy sobie na pytanie w jaki sposób ludzie podejmują decyzje? W życiu codziennym to emocje są zwykle czynnikiem przełomowym wpływającym na podjęcie decyzji w związku ze złożoną czy przytłaczającą sytuacją. Jednakże dla ekspertów/architektów podejmujących złożone decyzje, które mają długoterminowe konsekwencje, nie może być to zwykły impuls. Instynkt czy dobre przeczucie nie powinny wpłynać na podjęcie tak ważnej decyzji. Należy poznać wszystkie fakty niezbednę do wskazania odpowiedniej technologii dla naszego projektu.
Obecnie na rynku jest kilkadziesiąt technologii przesyłania wiadomości, niezliczona ilość ESBs (Enterprise Service Bus) oraz dziesiątki platform iPaaS (Integration Platform as a Service). Taka liczba prowadzi do pytania mającego na celu wskazać odpowiednią platformę do przesyłania wiadomości, która będzie dopasowana do naszych potrzeb. Jest to szczególnie istotne z perspektywy osób, które już zainwestowały w konkretną technologię. Czy powinniśmy zainwestować w narzędzie dopasowane do naszych potrzeb? Czy wymagania bizesowe zostały sformułowane poprawnie? Którze z narzędzi będzie właściwe dla naszej działalności? Co gorsza, wyczerpująca analiza może nigdy nie zostać zakończona z uwagi na liczbę dostępnych produktów. Jednakże staranność analizy danych ma tutaj kluczowe znaczenie z perspektywy średniej długości życia kodu napisanego na potrzebny biznesowe.
W tym artykule skupimy się na kluczowych elementach, obecnie najnowocześniejszych i najpopularniejszych produktów do jakich zaliczamy RabbitMQ oraz Apache Kafka. Każdy z nich ma własną historię powstania, ogólny zamysł produktu, cel projektowy, przypadki użycia, możliwości intergracji czy niezywkle ważne z naszej perspektywy odczucia związane z pracą w danej technologii. Początki projektowe są w stanie pokazać nam ogólny zamysł projektu i stanowią dobry punkt wyjścia dla dalszej analizy. Warto mieć również na uwadzę, że w artykule skupimy się na porównaniu podobnych funkcjonalności, które pozwolą nam wpłynać na dalsze decyzje.
Geneza
RabbitMQ jest "tradycyjnym" brokerem wiadomości, który implementuje różne protokoły przesyłania komunikatów. Jest to również jeden z pierwszych brokerów wiadomości o otwartym kodzie źródłowym, który oferuje rozsądną ilość funkcjonalności, bibliotek klienckich, narzędzi programistycznych oraz przejrzystą dokumentację. RabbitMQ został pierwotnie opracowany w celu implementacji protokołu AMQP - otwarty standard protokołu pozwalający na przesyłanie wiadomości z zaawansowanymi funkcjami routing’u. Protokół ten pozwolił na elastyczność w komunikacji pomiędzy serwisami wykonanymi w różnych technologiach.
Apache Kafka został opracowany w języku Scala a na początku wykorzystywany był jako sposób łączenia wewnętrznych systemów na platformie LinkedIn. W tym czasie LinkedIn przechodził przez proces zmiany stawiający na bardziej rozproszoną architekturę, musiał rozwiązać problem integracji i przetwarzania danych w czasie rzeczywistym. Wiązało się to z odejściem od monolitycznego (system monolityczny charakteryzuje się prostą, jednozadaniową strukturą, tj. system może wykonywać tylko jedno zadanie jednocześnie) rozwiązywania takich problemów. Kafka jest bardzo dobrze przyjęta w ekosystemie Apache Software Foundation (organizacja non-profit, której celem jest wspieranie produktów Apache typu open source) i jest szczególnie przydatna w architekturze event-driven (wzorzec architektury oprogramowania promujący produkcję, wykrywanie, zużycie zasobów oraz reakcję na zdarzenia):
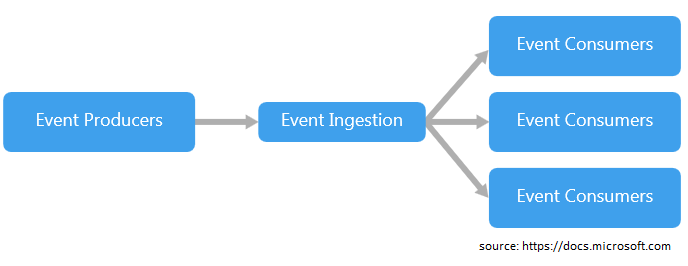
Architektura
RabbitMQ jest zaprojektowany jako broker komunikatów ogólnego przeznaczenia, wykorzystujący kilka odmian stylów komunikacji:
- point to point (bezpośrednia, z jednego miejsca do drugiego bez żadnych przystanków);
- request/reply (żądanie/odpowiedź);
- komunikacja typu pub-sub (wzorzec przesyłania wiadomości, w którym nadawcy wiadomości, tzw. wydawcy, nie przekazują wiadomości bezpośrednio do konkretnych odbiorców, zwanych też subskrybentami, ale zamiast tego kategoryzują opublikowane wiadomości w klasy, nie wiedząc, którzy subskrybenci otrzymają te wiadomości oraz czy je dostaną).
Produkt ten korzysta z podjeścia tzw. inteligentnego brokera/glupiego konsumenta, koncentrując się na konsekwentnym dostarczaniu wiadomości do konsumentów, którzy odbierają wiadomości w podobnym tempie w jakim broker śledzi stan konsumenta. Jest to produkt dojrzały, działający wydajnie, gdy jest poprawnie skonfigurowany oraz wpierany przez wiele różnych technologii, tj. Java, .NET, node.js, Ruby, PHP i wiele innych. Jest również rozbudowany o dziesiątki dostępnych wtyczek, którze poszerzają jego przypadki użycia i scenariusze integracji:
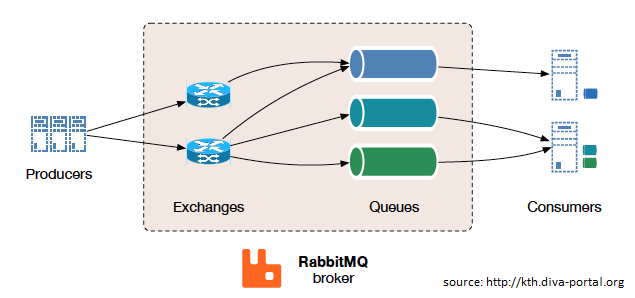
Komunikacja w RabbitMQ, w zależności od potrzeb, może być synchroniczna lub asynchroniczna. Wydawcy wysyłają swoje wiadomość do tzw. exchanges a konsumenci pobierają wiadomości z kolejek. Oddzielenie wydawców od kolejek za pomocą giełd zapewnia, że produceni wiadomości nie są obciążeni mechanizmem przekierowywania wiadomości (routing). RabbitMQ oferuje również wiele rozproszonych scenariuszy wdrażania (i wymaga, aby wszystkie węzły byly w stanie wskazywać na poprawne nazwy hostów). Można go skonfigurować w postaci klastrów wielowęzłowych w celu utworzenia tzw. federacji klastrów bez zależności do usług zewnętrznych (warto mieć na uwadzę, że niektóre wtyczki do tworzenia klastrów mogą korzystać z interfejsów API AWS, DNS czy Consul. Wróćmy jednak na chwilę do federacji klastrów. Koncepcyjnie jest to proste rozwiązanie. Sumujemy wiele klastrów Kubernetes i traktujemy je jako jeden klaster logiczny. Istnieje również dodatkowa płaszczyzna sterownia, która przedstawia klientom jednolity widok systemu:
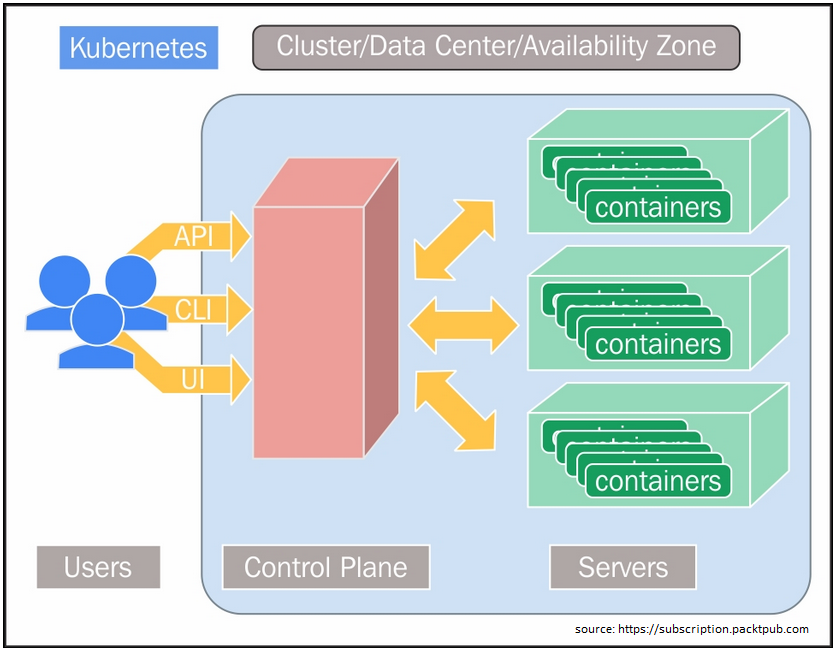
Apache Kafka jest przeznaczony do opisanej nieco wyżej komunikacji typu publish-subscribe. Głównym celem projektu jest umożliwienie obsługi danych czasu rzeczywistego pochodzących z wielu węzłów. Wymaganie mające zapewniać dużą przepustowość i redukcję opóźnień oparte jest jest ujednoliconej obsłudze strumieni wejściowych. W swoim zamyśle Kafka zapewnia trwały magazyn wiadomości, podobny do dziennika uruchamianego w klastrze serwerów, który przechowuje strumienie rekordów w kategoriach zwanych potocznie tematami.
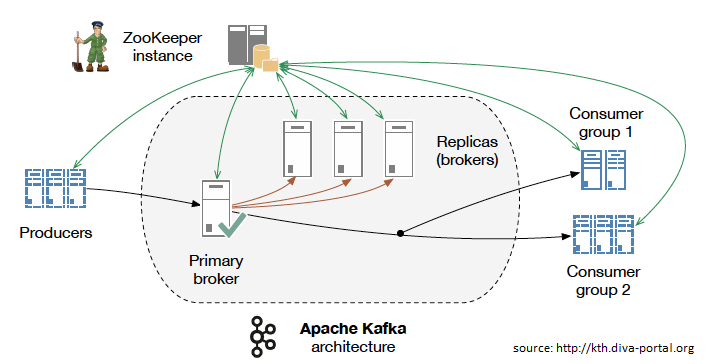
Każda wiadomość składa się z klucza, wartości oraz znacznika czasu. W odróżnieniu od RabbitMQ, Kafka używa odwrotnego podejścia, tj. głupi broker/inteligenty konsument, aby odczytać jego bufor. Kafka nie próbuje śledzić, które wiadomości były przeczytane przez każdego konsumenta – zachowuje tylko wiadomości nieprzeczytane. Warto być jednak precyzyjnym, wiadomości przechowywane są przez pewien określony okres czasu a konsumenci są odpowiedzialni za śledzenie ich lokalizacji w każdym dzienniku, tzw. consumer state. Odpowiednio zaimplementowany kod konsumenta (odbiorcy) pozwala obsługiwać dużą liczbę konsumentów oraz pozwala na przechowywania dużej ilości danych przy niewielkim obciążeniu. Analizując powyższy driagram możecie jednak zauważyć, że do swojego działania wymaga usług zewnętrznych, w tym przypadku jest to Apache Zookeeper, który jest uważany za ciężki w konfiguracji, obsłudze i zrozumieniu.
Wymagania i przypadki użycia
Wielu programistów zaczyna badać możliwości brokerów wiadomości, gdy zdają sobie sprawę, że muszą dokonać połączenia wielu rzeczy, a wzorce integracji takie jak wspólne bazy danych są niewykonalne lub zbyt niebezpieczne.
Apache Kafka został zaprojektowany i promowany na rynku w kierunku przetwarzania strumieniowego. Jedną z nowości jest dodanie strumieni Kafka Streams, które są opisywane jako alternatywa dla platform streamingowych, takich jak Apache Spark, Apache Flink, Apache Beam/Google Cloud Data Flow oraz Spring Cloud Data Flow. Przygotowana dokumentacja w dobry sposób opisuje najpopularniejsze przypadki użycia do których możemy zaliczyć śledzenie aktywności użytkownika na stronie, dane, agregacja dzienniku, przetwarzanie strumieniowe czy pozyskiwanie zdarzeń. Jednym z opisywanych przypadków użycia jest sposób użycia wiadomości – może to wywołać pewne zamieszanie. Warto zatem prześledzić najlepsze scenariusze przesyłania wiadomości dla Kafki:
-
strumień z punktu A do punktu B bez złożonego routing’u z maksymalną przepustowością rzędu 100k/sekundę+ dostarczaną w porządku podzielonym na partycje przynajmniej raz;
-
potrzeba dostępu do historii strumieniowej dostarczanej w kolejności podzielonej na partycje przynajmniej raz. Kafka jest trwałym magazynem wiadomości a klienci mogą uzyskać "powtórkę" strumienia zdarzeń na żądanie w przeciwieństwie do bardziej tradycyjnych brokerów wiadomości w których po dostarczeniu wiadomości jest ona usuwana z kolejki;
- Przetwarzanie strumienia (technologia pozwalająca użytkownikom przesyłać zapytania do ciągłego strumiania danych i szybko wykrywać warunki w krótkim okresie czasu od momentu otrzymania danych. Prostym przykładem przetwarzania strumieniowego jest dostęp do danych pochodzących z czujnika tempteratury i otrzymania ostrzeżenie, gdy temperatura osiągnie pewną wartość, np. punkt zamarzania);
-
Pozyskiwanie zdarzeń (event sourcing - zamiast przechowywania "bieżącego" stanu bytu w naszym systemie, przechowujemy strumień zdarzeń związany z danym bytem. Każde zdarzenie jest faktem, opisuje zmianę stanu, która nastąpiła w bycie. Dysponując takim strumieniem danych można dowiedzieć się jaki jest obecny stan obiektu, składając wszystkie zdarzenia związane z tym bytem – przechowując stan "bieżący" odczucamy wiele cennych informacji historycznych).
RabbitMQ jest brokerem wiadomości ogólnego typu często używanym w celu umożliwienia serwerom internetowym szybkiego reagowania na żądania, zamiast zmuszania ich do wykonywania procedur obciążających zasoby, podczas gdy użytkownik czeka na rezultat. Rozwiązanie to jest również dobre do dystrybucji wielu wiadomości do wielu odbiorców w celu ich konsumpcji lub równoważenia obciążenia (load balancing) pomiędzy serwisami pod dużym obciążeniem (20k+/sekundę). Kiedy jednak Twoje wymagania wykraczają poza przepustowość, RabbitMQ ma również wiele do zaoferowania:
- funkcje niezawodnego dostarczania wiadomości;
- routing;
- plugin federacji (idea kryjąca się pod tym pojęciem polega na przesyłaniu wiadomości pomiędzy brokerami bez wymaganego klastrowania. Takie zachowanie jest przydatne z wielu powodów. Więcej o zaletach takiego rozwiązania możecie przeczytać pod podanym adresem: https://www.rabbitmq.com/federation.html;
- bezpieczeństwo;
- narzędzia zarządzania.
Prześledźmy najlepsze przypadki użycia dla RabbitMQ:
- aplikacja musi działać z dowolną kombinacją istniejących protokołów, takich jak: AMQP 0-9-1, STOMP, MQTT, AMQP 1.0;
- potrzebujesz dokładniejszej kontroli spójności/gwarancji dla każdej wiadomości. Tutaj warto zaznaczyć, że ostatnio Kafka dodała wsparcie dla lepszej obsługi transakcji;
- wymagany jest zaawansowany routing, integracja wielu serwisów/usług z niebanalną logiką routing’u;
- aplikacja wymaga różnorodności w sposobie przetwarzania/dostarcznia wiadomości, tj. point to point, request/reply oraz publish/subscribe (typy operacji zostały opisane powyżej).
RabbitMQ może również rozwiązać kilka charakterystycznych przypadków użycia dla Apache Kafka - wymaga jednak do tego dodatkowego oprogramowania. RabbitMQ jest często używany wraz z Apache Cassandra, gdy aplikacja potrzebuje dostępu do historii strumienia.
Środowisko programistyczne
RabbitMQ oficjalnie obsługuje Java, Spring, .NET, PHP, Python, Ruby, JavaScript, Go, Elixir, Objectiv-C, Swift - z wieloma klientami i narzędziami deweloperskimi za pomocą wtyczek przygotowywanych przez społeczność. Biblioteki przygotowane dla RabbitMQ są rozwinięte i dobrze udokumentowane.
Apache Kafka robi postępy w tym kierunku jednakże udostępnia tylko klienta Java. Z drugiej strony rośnie katalog otwartego oprogramowania przygotowywanego przez społeczność a także pakiet SDK umożliwiający zbudowanie własnej integracji systemu. Większość konfiguracji odbywa się za pomocą plików .properties lub za pomocą odpowiedniej implementacji.
Popularność obu tych narzędzi na również wpływ na dostawców oprogramowania, którzy dbają o to, aby RabbitMQ i Kafka działały dobrze w oparciu o ich technologię.
Bezpieczeństwo i zarządzanie
Oba z tych punktów są mocną stroną RabbitMQ. Wtyczka do zarządzania serwerem zapewnia interfejs API HTTP. Interfejs użytkownika oparty na przeglądarce pozwala na monitrowanie i zarządzanie serwerem. Zarządzanie jest również możliwe przy użyciu linii poleceń CLI. Jeżeli zależy nam na długoterminowym przechowywaniu danych musimy posłużyć się zewnętrznymi narzędziami takimi jak CollectID, Datadog czy NewRelic. RabbitMQ zapewnia również API do zarządzania i rozwiązywania problemów z aplikacją. Oprócz obsługi TLS RabbitMQ dostarczany jest z RBAC wspieranym przez wbudowany magazyn danych, LDAP lub zewnętrznych dostawców opartych o protokół HTTPS. Dodatkowo uwierzytelnianie obsługiwane jest użyciu certyfikatu x509 zamiast kombinacji nazwy użytkownika i hasła. Dodatkowe metody uwierzytelniania mogą łatwo zostać opracowane przy pomocy wtyczek.
Obie te domeny w przypadku Kafki są ciągle udoskonalane. W ostatnich wersjach otrzymujemy wsparcie dla SSL/TLS, uwierzytelnianie za pomocą SSL lub SASL oraz autoryzację przy pomocy ACL. Jest to znaczące ulepszenie w porównaniu do poprzednich wersji w których można było zablokować dostęp tylko na poziomie sieci co nie działało zbyt dobrze w przypadku udostępniania czy współdzielenia.
Zarządzanie w przypadku Kafki odbywa się za pomocą CLI składającego się z odpowiednich skryptów, plików właściwości i specjalnie sformatowanych plików JSON. Dane emitowane przez dostawców czy odbiorców odbywają się za pośrednictwem Yammer/JMX, ale nie zachowują żadnej histori co w praktyce oznacza korzystanie z zewnętrznego systemu monitrowania. Korzystając z tych narzędzi jesteśmy w stanie zarządzać partycjami i tematami, sprawdzić pozycję offsetową odbiorcy (nie jest to klucz ale automatyczna pozycja rekordu. Jest to mechanizm śledzący liczbę rekordów pobranych z partycji tematu dla określonej grupy odbiorców) oraz korzystać z funkcji takich jak HA oraz FT, które są zapewniane przez oprogramowanie Zookeeper.
Wydajność
Kafka prezentuje się świetnie przy wydajności 100k/sekundę – często jest to czynnik decydujący przy wyborze tej technologii. Oczywiście ten współczynnik jest trudny do określenia ponieważ zależy od wielu czynników: środowiska i sprzętu czy rodzaju obciążenia.
20 tysięcy wiadomości na sekundę nie jest trudne do przepuszczenia przez kolejkę RabbitMQ. Dodatkowo dostajemy gwarancję dostarczenia wszystkich wiadomości. Kolejka jest wspierana przez jeden wątek języka programowania Erlang, który zostaje zaplanowany wspólnie na puli natywnych wątków systemu operacyjnego. Pojedyncza kolejka nigdy nie wykona więcej pracy niż jest w stanie uruchomić cykli procesora (CPU) – staje się więc naturalnym "wąskim gardłem" lub tzw. "szyjką butelki".
Zwiększenie przepustowości często łączy się z poprawną implementacją mechanizmu współbieżności dostępnego w danym środowisku programistycznym. Jako przykład możemy tutaj powiedzieć o dzieleniu ruchu na wiele kolejek za pomocą sprytnego routing’u (aby różne kolejki mogły działać równocześnie). Tak zaimplementowane przetwarzanie współbieżne było nawet w stanie obsłużyć 1 000 000 wiadomości na sekundę w środowisku RabbitMQ - wynik został jednak osiągnięty przy dużej ilości zasobów, mówimy tutaj o około 30 węzłach. Dla większości użytkowników wystarczającą ilością są klastry składające się z trzech do siedmu węzłów.
Podusmowanie
Cel artykułu był niezwykle prosty: pokazać różnice pomiędzy narzędzami, pokazać ich mocne i słabe strony, skupić się na porównaniu z prostymi przypadkami użycia. Mam nadzieje, że cel został osiągniety a wiedza przedstawiona tutaj będzie stanowiła doskonałe podłoże podstawowej, ale jednocześnie solidnej dawki wiedzy, dotyczącej obu tych narzędzi.
